
In part 1 of this project, I introduced my method for digitising my diaries, this involved a multi-step process that chained Google's OCR API to an LLM query which produced a rough transcription that I could correct manually.
The first update only covered the first two diaries (out of 6). I've since corrected the entire set of diaries which gives me a grand total of 215,200 words across 997 entries spanning seven and half years of my life, from age 17 to 24.
This full corpus gives me more opportunities for analysis than in the original post so without further ado, let's dive in.
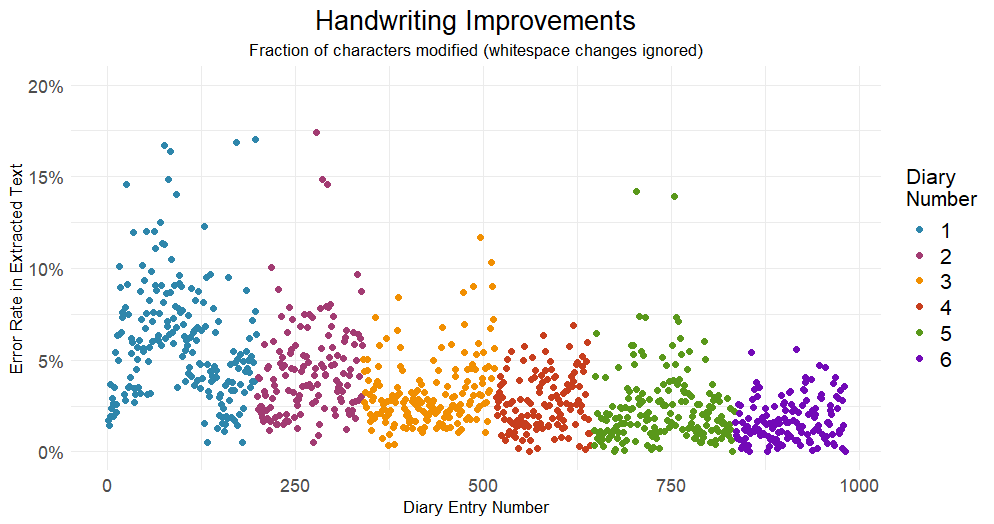
As I went through the corrections process, it felt that it was becoming faster to correct each page. I wasn't sure if this was because I was getting more experienced or because the transcripts were more accurate.
We can see that the latter is correct, the rate of corrections decreased significantly over time as my handwriting improved. Several pages in the last diary needed no corrections whatsoever!
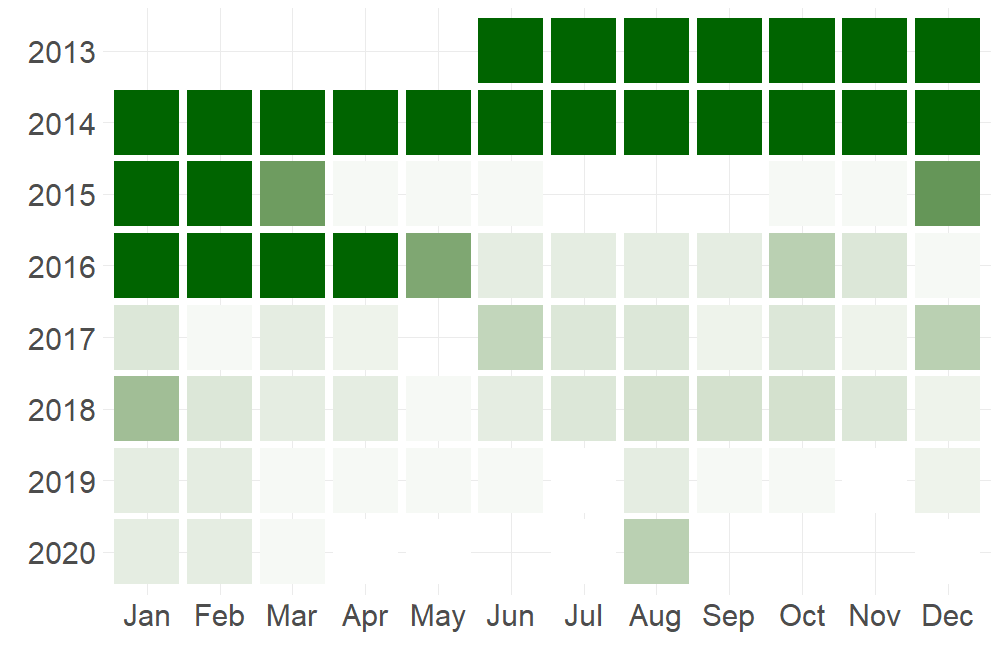
The diary coverage is shown here. Solid green means that I wrote an entry for every day that month. There were two spurts from 2013-2015 and in early 2016 when I was writing in my diary daily. Separated by a break in the Summer of 2015.
Outside of these stints I would be updating my diary regularly, but only once or twice a week.
To analyse the sentiment of the diary entries, I used the Afinn dataset. This is a manually constructed set of words that are associated with positive or negative sentiments in text. E.g. "thrilled", "superb", "outstanding" all get scores of +5, at the negative end are a bunch of slurs & swear words that I won't repeat here.
This approach is obviously limited ("not bad" would get a negative sentiment) but is simple enough to implement and probably broadly gets the sentiment of each day correct.
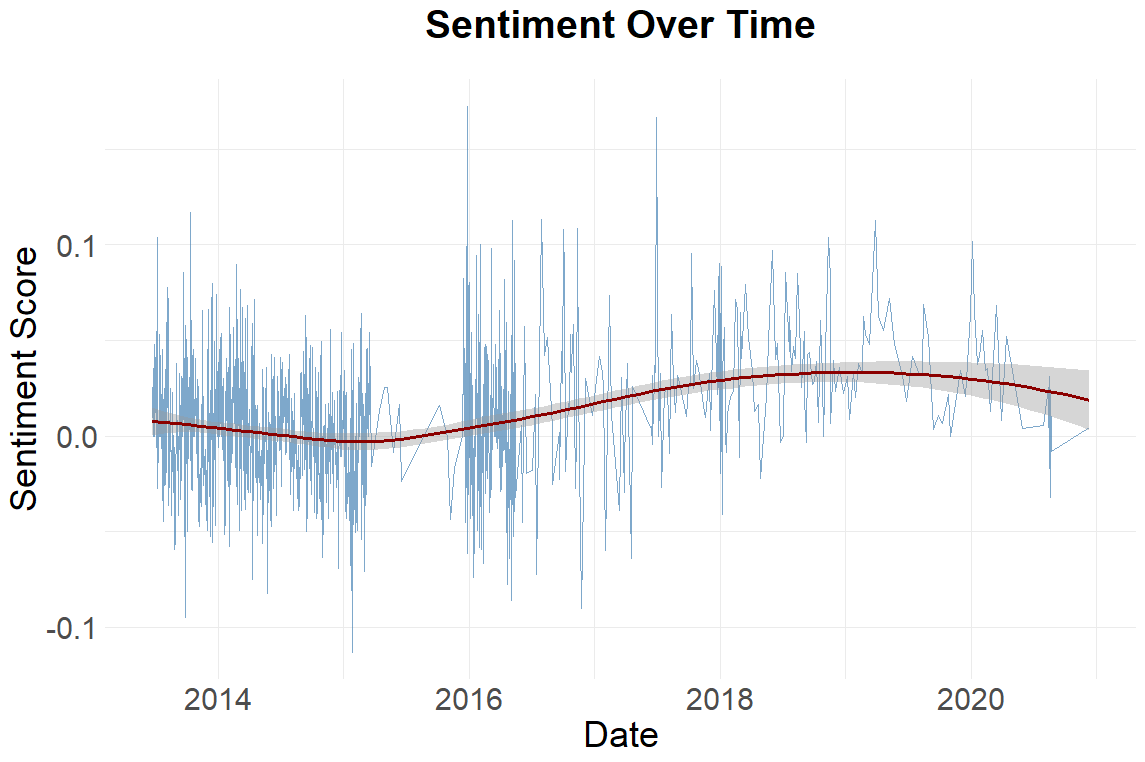
In the graph on the right the average sentiment score (net sentiment / total words) is shown over time.
Starting in around 2017, the sentiment score of diary entries becomes more positive on average
We can go further than sentiment alone. I've used the NRC Word-Emotion Association Lexicon to investigate how my emotional state changed throughout the entries. This works similarly to the Afinn sentiment analysis from above, but words are associated with certain emotions rather than a positive or negative sentiment value.
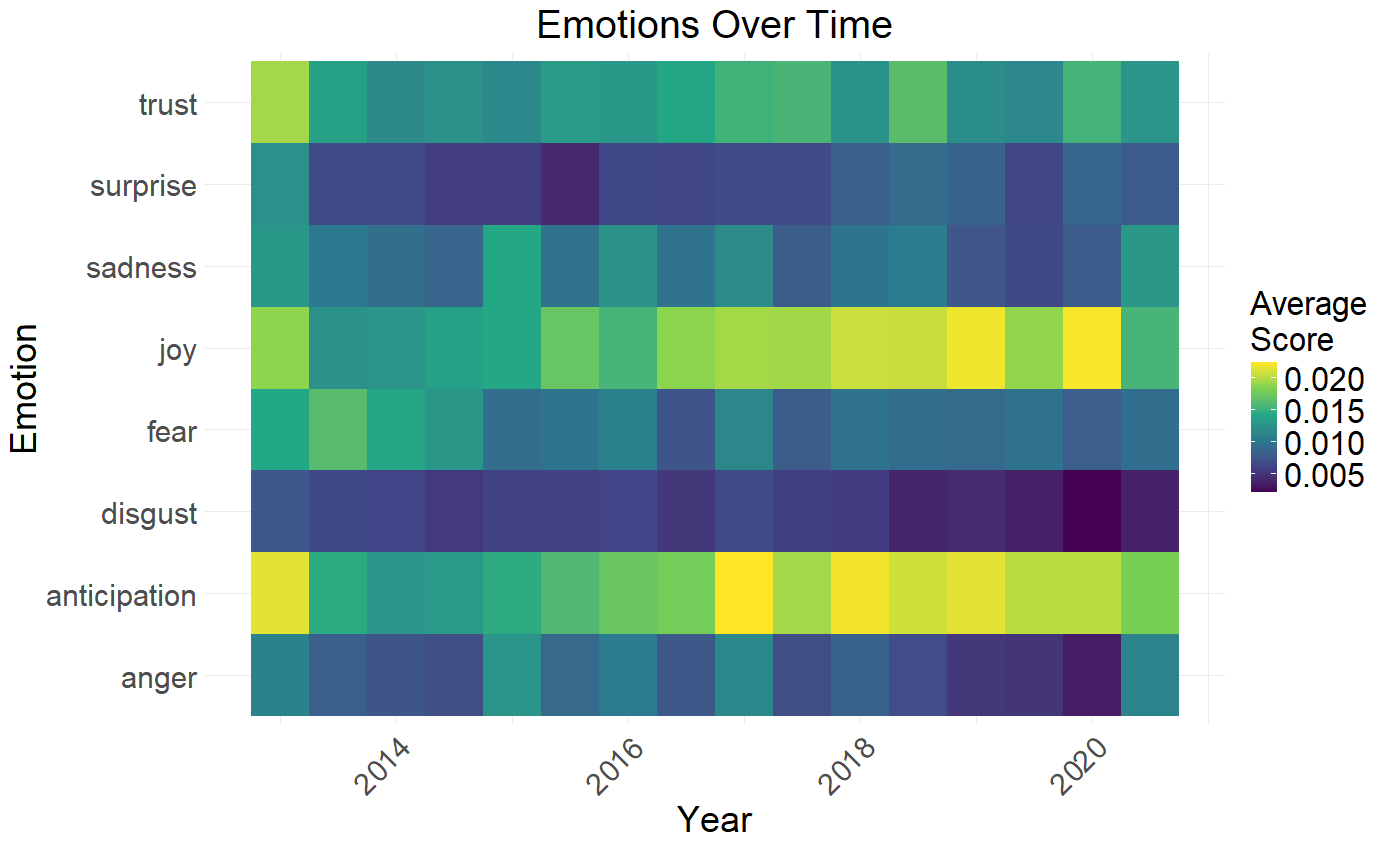
The colour scale on this graph shows the average rate of words associated with each emotion. These are average across 6-month periods to get a large sample of how they change over time.
We can see that after 2017 the "Joy" and "Anticipation" emotions become stronger (guess when I met my wife...) with disgust dropping at later times too.
One last thing we can try is using an LLM to evaluate each diary entry, giving a score between 0 and 10 across a variety of different metrics. I used Claude to generate the following prompt and ran it across all 997 of my diary entries:
You are an expert psychological analyst specialising in diary entry assessment. Your task is to analyse the provided diary entry and return quantitative scores across multiple dimensions.
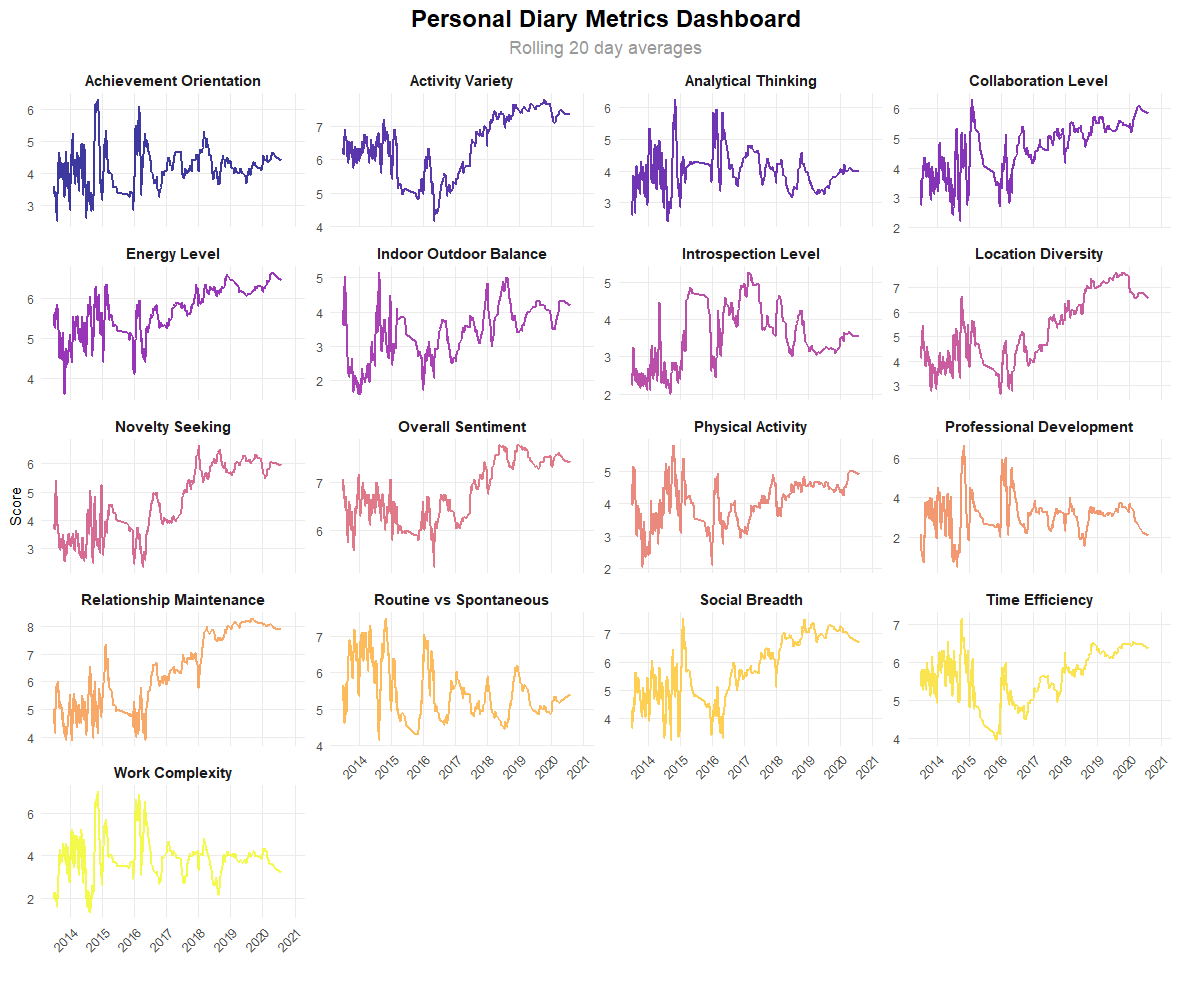
The rolling averages of each metric are shown in the graphs below. The width of the moving average is 20 entries. It's impressive to see how the "Overall Sentiment" trendline mirrors that from the much more simplistic Afinn approach, with an increase across 2017 that leads to a higher baseline thereafter.
The same trend can be seen in "Activity Variety", "Novelty Seeking", "Location Diversity", "Social Breadth", "Relationship Maintenance", and to a lesser extent "Energy Level". This was also when my diary entries shifted from daily to more infrequently which could explain some of the variety/diversity metrics being boosted.
Clear seasonality can be seen in the "Indoor Outdoor Balance", "Routine vs Spontaneous", "Work Complexity" and "Professional Development". Compare the winters (the gridlines) to the summers (the space in the middle between the gridlines). The summers feature more spontaneity, less work and development, and more time outdoors.
Hapax Legomenon is the Greek term for a word that is only mentioned once in a text or corpus. This is often relevant for scholars of ancient languages where a hapax legomenon can be impossible to translate. The term came to my attention when it was the answer to a University Challenge question that became a semi-viral meme. I endeavoured to appear on that TV show several times in my university days, getting onto my college team but failing to pass the television interview four years in a row.
The contestant in that Youtube clip, "Loveday", actually appears as a hapax legomenon in my diaries, his singular appearance being when I met him outside the van of life eating cheesy chips off the floor after a night out.
Click here for a file containing a full list of all the Hapax Legomena (hapaxes?) in my diaries.
I'm very surprised at how clear the longitudinal trends are across these diaries. From handwriting quality to the emotions I was feeling, it's apparent that I was changing significantly over the course of their writing. No doubt I've continued to change since their completion too.
It's great that AI tools have allowed me to probe my own history with such ease. I wouldn't have been able to transcribe these diaries from scratch and I now I can search for any moment with ease.
It's rare to be able to generate such a novel & personalised dataset and the analysis process has been fun, even just reading back through everything and remembering old times. I'd recommend trying it with your own journals if you have a collection!